From Thonburian Whisper to Multimodal Applications

Thonburian Whisper
Hello January 2025! Thai automatic speech recognition (ASR) has made significant strides in recent years. I am particularly impressed by the development from Ekapol's lab on foundation techniques in ASR, NECTEC on releasing Pathumma (series of models including LLM, ASR, Multimodal models), and SCB 10X on recently releasing Typhoon 2 (series of LLM and multimodal LLMs). Our lab is also excited to be a part of the journey by releasing Thonburian Whisper, a fine-tuned Whisper for Thai.
Origins
In December 2022, our lab and Wordsense (an affiliated company with Looloo Technology) released Thonburian Whisper as a part of Huggingface's Whisper fine-tuning event. When we first released the model, our goal was to address the challenges that vanilla Whisper models faced with Thai speech. Through careful combination of audio datasets, strategic augmentation, and improved segmentation, we achieved significant improvements in Word Error Rate (WER) across different model sizes. The distilled models proved particularly interesting, achieving strong performance with less than 1,500 hours of audio data. We recently publish our model at ICNLSP 2024 where we have grown community using our model on Github.
Community Adoption
It's been incredibly encouraging to see the adoption and extension of our work by the Thai AI community. We'd like to particularly thank the team at NECTEC for their work on Pathumma Whisper, which builds upon and references our Thonburian Whisper approach. We also would like to thank
- DMIND, a national depression screening application, developed from AIMET
- and PresScribe, application that summarizes patient conversations into medical records
that use our model as a base model. If you use our model for Thai speech-to-text application, please feel free send message.
Expanding into Multimodal LLM
The impact of Thonburian Whisper has also extended beyond pure speech recognition. We're particularly excited about its integration into larger multimodal language models. The recent Typhoon2-Audio project demonstrates this perfectly, using a fine-tuned version of Thonburian Whisper Large as part of its speech encoding stack with BEATs for audio encoder. We highly recommend reading their Arxiv paper where they went in details of their Audio LLM training recipes.
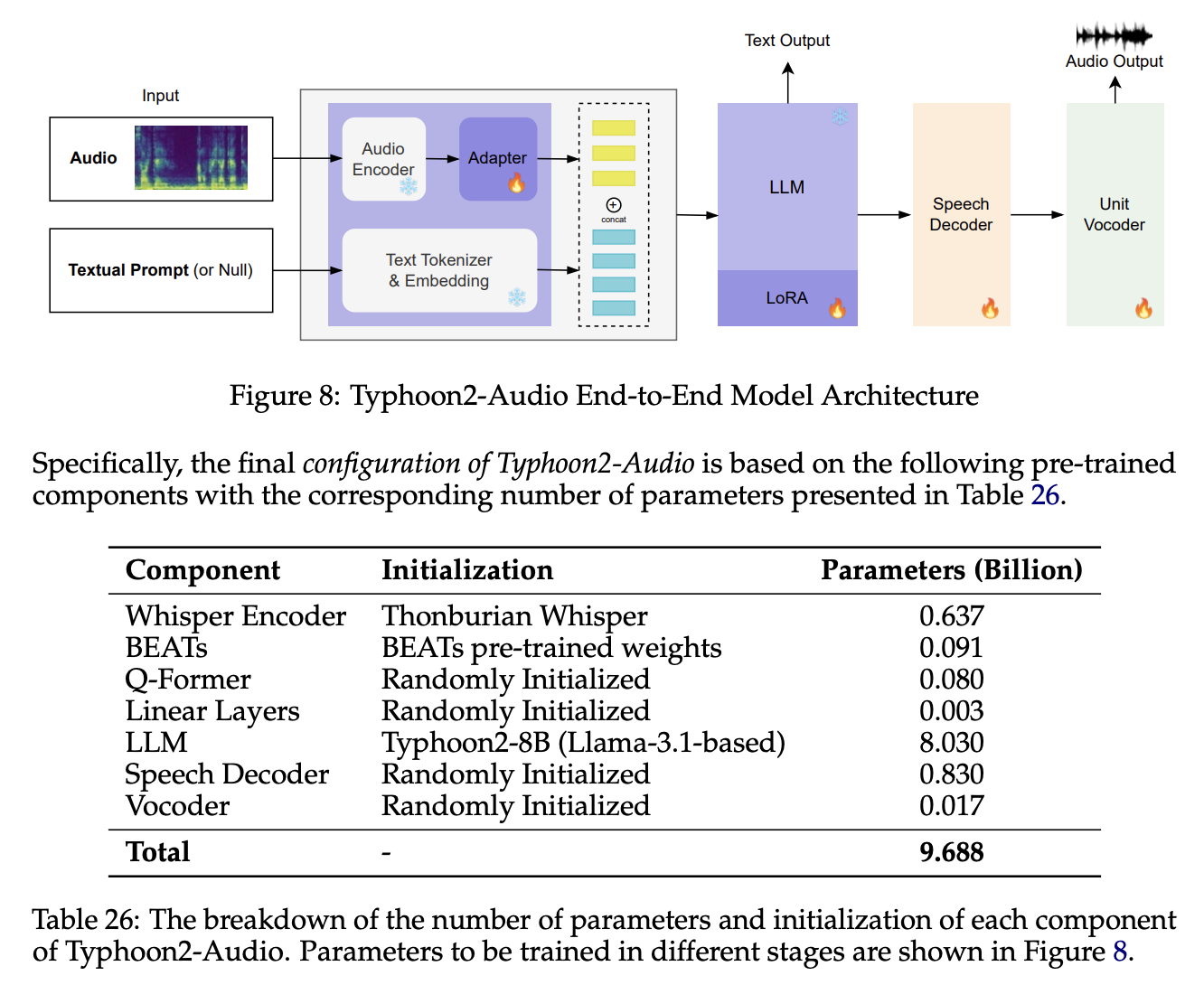
Typhoon 2 audio uses Thonburian Whisper Large as their encoder. Reference: Typhoon 2 https://arxiv.org/pdf/2412.13702.
Looking Forward
As we continue to see Thonburian Whisper being used in Thai commmunity, we see a great open collaboration in advancing Thai ASR community. Whether it's being used for direct speech recognition, serving as a component in larger multimodal systems, or inspiring new approaches, each application helps push the field forward. We encourage researchers and developers to continue exploring and building upon these foundations. The code and models are available at our GitHub repository. Hope we see a lot more development in speech community coming up this year!